
想知道一个网站的情况,那么肯定是离不了对网站进行分析。而分析网站,肯定离不开数据,一般情况我们用gsc就可以了。但是gsc是有一定延迟的,如果延迟个三五天,很可能就会出现问题了。想要即时性的,最好的方法就是直接观察网站日志,目前市面上的网站日分析工具有光年、loghao、Log File Analyser等来做蜘蛛分析。
光年日志分析工作、loghao多是用来分析百度系的,而Log File Analysery 主要分析google的日志。

蜘蛛分析工具SEO Log File Analyser分名叫作:SEO Log File Analyser | Screaming Frog
在这里电商新媒体营销第十八掌第大家推荐的是SEO Log File Analyser | Screaming Frog破解版,有SEO Log File Analyser | Screaming Frog的激活码,这里就直接放百度云盘吧,方便大家进行下载。
因为软件是英文的,怕大家不懂,我就直接简单翻译了一下,别外就是告诉大家,用SEO Log File Analyser | Screaming Frog分析网站日志,应该看哪些东西。
注意:网站日志一般放在网站的根目录,一般名字为logs或log,里面的文件。如图:
格式是.gz的压缩包,可以解压一下,解压后用计事本打开,可以看到里在的代码。如图:
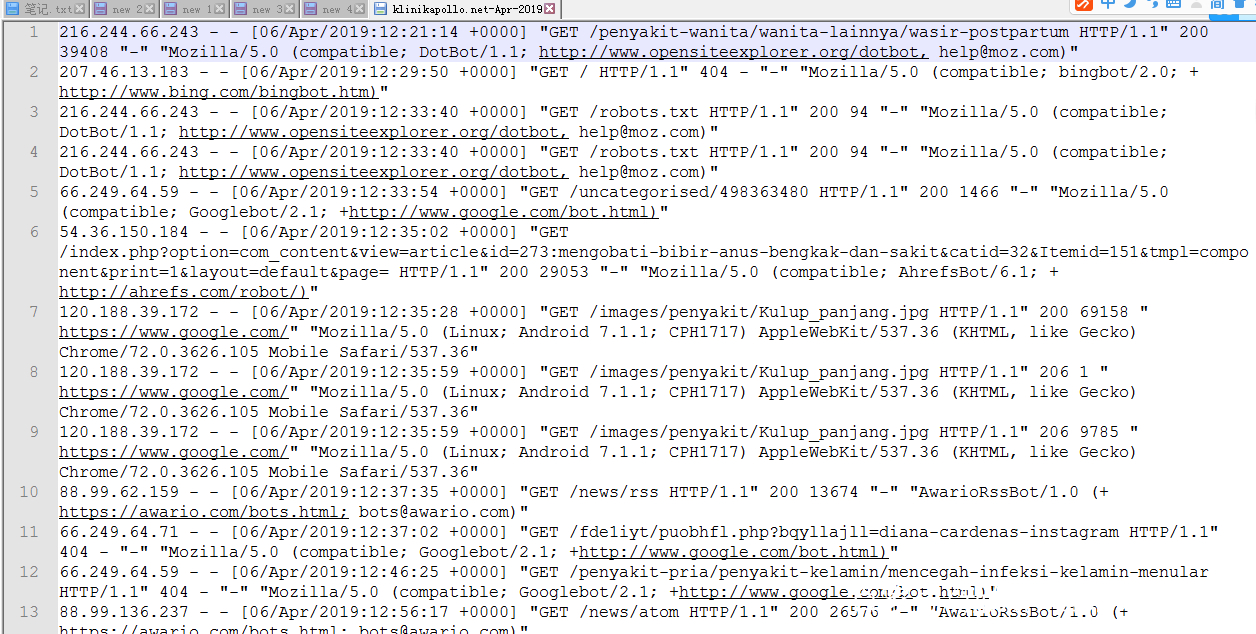
网站分析(txkt)
一、overview(概况)
1.Unique URLs (唯一的网址)
2.Unique URLs per day(每日唯一的网址)
3.Total events(总事件)
4.Events per day(每日活动)
5.Average bytes (平均字节数)
6.Average time taken (ms) (平均所用时间(毫秒))
7.Errors (错误)
8.Provisional (1xx) 临时(1xx)
9.Success (2xx) 成功(2xx)
10.Redirection (3xx) 重定向(3xx)
11.Client Error (4xx) 客户端错误(4xx)
12.Server Error (5xx) 服务器错误(5xx)
二、urls(所有url)
1.html
(1)averge bytes【上传+下载的量】
观察里面的的大小,如果突然太大或者是太小,如果是突然为0,可能当前页面没有抓到东西
(2)time taken【加载时间】
如果加载时间过长,如果内容不是太多,可能是因为考虑是不是代码问题
(3)last response codes(相应结果)
果是200是正常,如果4xx说明网页,如果是5xx可能是服务问题
(4.)如果手机蜘蛛多,说明手机端做的好,或者是手机端优先。
2.css
(1).看一下!主要是看扫描时间,时间太长
(2).相应时间,如果时间过长,看一下url是不是可以打开。
(3)蜘蛛会扫css,确定网站的样式
三、 response codes(相应结果)
(1.)2xx
(2.)3xx
(3.)4xx
(4.)5xx
四、user agent(用户代理)
(1)了解蜘蛛类型
(2.)unique urls
五、directories(目录)
袋子理论,看一下蜘蛛一共抓了哪些目录,哪些目录抓的多,如果说一些不需要抓的反复抓,可以直接robots屏蔽。
袋子理论,一个袋子时面装苹果的数量是一定的,如果装了坏苹果,就装不了好苹果了。网站也是,网站蜘蛛都扫无用的目录了
哪么就没精力搜其他目录了。例如:wp-admin可以直接屏蔽。
六、events(事件)
总:(1)对于新站,最好是每天查看一下,可以知道每天的每个时间段抓取的情况。如果平时是1000个蜘蛛,而其中某一天蜘蛛很低,甚至为0,哪说明可能网站有可能会被k站。
(2)如果蜘蛛一天比一天多,而且深度也够深,说明网站数据整体不错。
这些只是数据,具体优化还是自己优化。可以处理的是404、css代码问题
(3)404页面的处理方式:1.直接301到首页 2.重新写一个同url的新页面。